В машиночитаному форматі дані можна отримати:
– як табличні дані CSV або інший формат із роздільниками;
– як файли електронних таблиць Excel (.xls, xsls(x)), OpenDocument (.ods) тощо.
При цьому дані не завжди можна використати такими, якими вони прийшли, але принаймні дозволяє одразу перейти до їх очищення.
Разом з тим досить часто отримані дані надходять не в машиночитаному вигляді. Це можуть бути, зокрема:
– начитка даних на диктофон;
– паперові машинописи і навіть рукописи;
– файли зображень зі сканами документів (.png, .gif, .jpg, .jpeg, .bmp, .tiff тощо);
– багатосторінкові скановані документи – PDF і DjVu без експортованого тексту (лише зображення сторінок) та багатосторінкових TIFF;
– мультимедійні презентації у відеоформатах;
– документи PDF і DjVu з експортованим текстом;
– презентації PowerPoint (.ppt і .pptx) та OpenDocumentFormat (.odp),
– документи офісних текстових редакторів, найчастіше Microsoft Word (.doc і .docx), рідше RTF й OpenDocumentFormat (.odt);
– текстові файли (.txt);
– вебсторінки, що містять дані в тій чи іншій формі.
Робота з начиткою даних
Існують програми перетворення мовлення на текст, зокрема й такі, що підтримують українську мову, наприклад FSM Soft Speech to Text Translator TTS (для Android) чи CyberMova VoiceTypist (для Windows), але їх створено як альтернативу введенню з клавіатури, для їх надійного функціювання начитка має бути нешвидкою, із чіткими паузами між реченнями тощо. За допомогою розпізнавання голосу ми отримаємо неструктурований текстовий файл, роботу з даними в якому розглянуто нижче. У результаті ручного введення можливо одразу наповнювати електронну таблицю, що в більшості випадків виявиться і простішим, і швидшим, і надійнішим.
Робота з даними на папері
Коли дані записано від руки на папері, або є сильно пошкоджений машинопис із накресленими олівцем таблицями, їх доведеться вводити вручну, бо жодна розпізнавальна програма не впорається з такою роботою досить надійно. Але навіть тоді ці документи варто належним чином оцифрувати для того, щоб мати їх копію й дати можливість ознайомлення з ними іншим.
Посторінкові оригінали можна сканувати за допомогою планшетного сканера. У параметрах сканування треба виставити достатню роздільну здатність. Деякі планшетні сканери дозволяють сканувати й прозорі оригінали.
Нерівні оригінали, такі, як товсті книжки, що погано розкриваються, та документи, що можуть бути пошкоджені вкладанням у сканер, цілком можна перезнімати на цифрову фотокамеру. Отримані зображення варто зберігати у файлах без компресії або з компресією без втрати якості. Наприклад, формат PNG – найбільш придатний, для формату TIFF треба обирати LZW-компресію, а формату JPEG варто уникати, оскільки він створює додаткові шуми і паразитні контури коло літер. Бажано дотримуватися правила «одна сторінка – один файл».
Робота з текстовими й табличними даними у зображеннях
Зображення документів, за винятком рукописних і дуже пошкоджених, добре піддаються зчитуванню засобами програм розпізнавання тексту (OCR). Деякі з них, такі, як вільнодоступний Tesseract, без спеціальних засобів розпізнають таблиці як простий текст. Більш ефективні розпізнавальні програми, зокрема комерційний ABBYY Fine Reader, можуть розпізнавати таблиці й експортувати ці дані.
Тексти після читання розпізнавальною програмою потребують перевірки, і навіть дуже просунута програма може помилятися, наприклад, ідентифікувати літери як інші літери, групи літер як одну літеру або зчитувати бруд і пошкодження як символи. Деякі з таких помилок системні, зокрема, дуже типове нерозрізнення нуля й літери «О». Отже, якщо даних небагато, а якість розпізнавання низька, продуктивнішим може виявитися перенабирання тексту вручну.
Робота з графіками й діаграмами у зображеннях
Не всі дані в зображеннях є таблицями чи текстом. Частина з них є графіками, діаграмами й іншими візуалізаціями. Деякі з них неможливо перетворити на цифри інакше, ніж вручну, а деякі, це стосується багатьох прикладів інфографіки, можуть не містити коректних даних взагалі.
Проте, прості графіки, стовпчасті діаграми, гістограми тощо цілком придатні до автоматичного й напівавтоматичного оброблення за допомогою спеціальних програм.
Чи не найпотужнішою з них і безоплатною платформо-незалежною є браузерна програма (онлайн-сервіс) Web Plot Digitizer. Цей засіб може обробляти зображення графіків у декартових і полярних координатах, стовпчикові діаграми, гістограми, тренарні діаграми і мапи, а також заміряти кути й відстані в мапах. WebPlotDigitizer підтримує ручний і автоматичний режими роботи. Отримані в результаті оцифровування дані Web Plot Digitizer зберігає у CSV-форматі.
Робота з багатосторінковими документами (PDF, DjVu, TIFF)
Формати багатосторінкових документів створювалися в першу чергу для збереження зовнішнього вигляду документа в усіх його особливостях. Багатосторінковий варіант TIFF, по суті, є просто набором зображень, не обов’язково одного розміру, колірності й якості, збереженим в одному файлі. Формат DjVu влаштований дещо інакше й, крім зображень сторінок документа, може містити текст, доступний для експорту. Формат PDF є, по суті, іншою формою мови PostScript, що використовується для якісного друку, тому в PDF, отриманому з електронного джерела (офісного текстового редактора, видавничої системи тощо), має бути доступний для експорту текст. Але, в PDF можна вкласти скановані зображення сторінок.
Якщо багатосторінковий документ не має доступного для експорту тексту, а наявна розпізнавальна програма текстів не вміє відкривати такий файл чи не бачить його багатосторінковість, його треба розділити на окремі посторінкові файли зображень.
Багатосторінковий TIFF можна розділити на окремі файли, наприклад, за допомогою онлайн-інструмента Free Online Tiff Image Split. Також можна скористатися командою convert multipage.tif -scene 1 splitted_%02d.png пакета ImageMagick.
Отримані з електронного оригіналу PDF-файли можуть виглядати охайно й сприйматися людиною, часто це реальні макети паперових публікацій, але при цьому видавати артефакти (зокрема, нові рядки замість пробілів, наприклад, латиницю з діакритикою замість кирилиці – це наслідок використання шрифтів з неунікодовим іменуванням гліфів замість літер. Але навіть із правильних PDF-файлів табличні дані часто виводяться мало- або не придатним для оброблення чином, наприклад так:
AsciiSignAsciiSignAsciiSign048005020524049Для якісного експорту табличних даних можна використовувати такі інструменти, як Tabula. Цю доступну для Windows, MacOs і Linux вільну програму написано на Java, тож вона вимагає наявності Java-середовища в операційній системі. Tabula запускається у браузері, скерованому на http://127.0.0.1:8080/ і надає «вебсторінковий» інтерфейс, в якому можна завантажити оброблюваний PDF, автоматично чи вручну виділяти ділянки з даними й отримати CSV. Та ж таблиця після оброблення Tabula виглядає так:
Ascii ,Sign ,Ascii ,Sign ,Ascii ,Sign048 ,0 ,050 ,2 ,052 ,4049 ,1 ,051 ,3 ,053 ,5Крім CSV, Tabula експортує TSV (значення, розділені табулятором) і JSON.
Робота з електронними документами та презентаціями
Якщо дані містяться в документі офісного редактора на кшталт DOC, DOCX, ODT, RTF тощо або у презентаціях типу PPT чи ODP, їх можна перенести до електронної таблиці копіпейстом.
У мультимедійних презентаціях і фільмах можна вихоплювати стоп-кадри, де зображено таблиці чи графіки, зберігати їх у графічні файли й обробляти, як указано вище у пунктах «Робота з текстовими й табличними даними у зображеннях» і «Робота з графіками й діаграмами у зображеннях».
Вебскрейпінг – отримання даних із вебсторінок
Публікація даних в інтернеті не завжди означає їх наявність у машиночитаному форматі. Як діяти у випадках, коли ці дані «сховано» у зображеннях графіків, сканах документів тощо, розглянуто вище. Але досить часто дані нібито є, і їх включено до тіла HTML-сторінки, тобто позначено певними елементами розмітки. Ідеальним є випадок, коли їх закодовано у таблицю, тоді можна обійтися копіпейстом. Так само не викликає великих проблем випадок, коли їх закодовано списком – він перетворюється на CSV простим пошуком і заміною. Але інколи дані структуровано, але не у вигляді таблиці чи списку, наприклад, для кожного запису (рядка потрібної таблиці) на сайті існує окрема сторінка.
Гарним прикладом такої ситуації може бути практично будь-який інтернет-магазин, де інформація про товар, назва, параметри чи характеристики, ціна розташовані (і закодовані засобами HTML) однаково для всіх товарів, але кожен товар чи група з кількох товарів доступні як окрема сторінка.
Копіювання таких даних вручну – нескладний, але непродуктивний і повільний процес, ускладнений неминучими помилками. Тому для такої роботи треба використовувати скрейпінг (від англійського scraping – зачища́ння») або вебскрейпінг – різноманітні програмні засоби від простих скриптів до потужних онлайн-сервісів.
Володіючи навичками програмування і розуміючи спосіб, у який кодовано дані на вебсайті, можна написати спеціальну програму, яка буде збирати потрібні дані. Приклади таких програм наявні багатьма мовами програмування, від Python до Common LISP і від R до Prolog. Принцип дії скрейперів в основному однаковий: за допомогою HTTP-протоколу програма отримує сторінку або множину сторінок (тому важливо розуміти, як будується URL потрібного діапазону сторінок) і за допомогою тих чи інших засобів її аналізу «виймає» потрібні дані (тому важливо знати, як саме поле даних закодоване в сторінці).
Обмеження скрейпінгу
Не завжди дані, що їх можна перенести з вебсторінки вручну, доступні до скрейпінгу. На заваді автоматичному обробленню можуть стати:
– неструктурний або нерегулярно структурований HTML. Таке може ставатися внаслідок створення сторінок візуальними або офісними редакторами з орієнтацією суто на зовнішній вигляд сторінки;
– системи автентифікації користувачів, мета яких – перешкодити автоматичному доступу. Це можуть бути системи кодів CAPTCHA або системи платного доступу;
– системи, що працюють у режимі сесій і використовують куки (cookies) браузера, щоб стежити за тим, що робить користувач;
– блокування системними адміністраторами доступу до масиву даних;
– зміна способу структурування даних внаслідок редизайну сайту. Найпідступнішим є те, що такий редизайн може бути невидимим для людини-читача, але повністю збивати програму-скрейпер.
Наприклад, з якихось своїх міркувань, розробники сайту почали подавати списком те, що раніше подавали потоком іменованих блоків. З точки зору семантичної етики, вони зробили як краще, а створений для попереднього дизайну скрейпер не вичитає зі сторінки нічого.
Скрейпер в Google Spreadsheets
Почнемо з простого. Примітивний скрейпер міститься вже у табличному редакторі Google Spreadsheets. Тут є функція Import HTML, яка дозволяє завантажувати в документ прості таблиці або списки.
Синтаксис функції
IMPORTHTML (url, query, index), де url – посилання на сторінку з таблицею; query – запит, може бути або table (таблиця), або list (список); index – порядковий номер таблиці чи списку на сторінці (важливо в тих випадках, коли таблиць чи списків на сторінці багато).
Таким чином, створивши таблицю в Google Spreadsheets, достатньо в комірку (наприклад верхню ліву, А1) вставити =IMPORTHTML("https://en.wikipedia.org/wiki/Demographics_of_India"; "table"; 4) і натиснути Enter.

У результаті чого ми присвоюємо цій комірці значення функції IMPORTHTML із заданими параметрами, і функція витягає в нашу електронну таблицю четверту таблицю зі сторінки вікіпедії про демографію Індії.
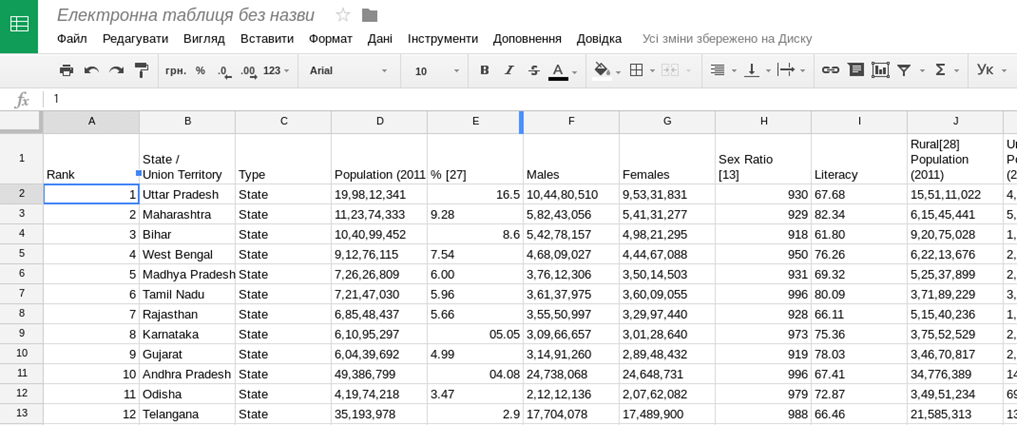
У випадках, коли дані на сторінці добре структуровані, функція IMPORTHTML суттєво полегшує життя і дозволяє швидко перейти власне до аналізу даних.
Import.io
Програма Import.io дозволяє витягувати дані зі сторінок в інтернеті й зберігати їх у таблицю або файл із даними для подальшого використання. Сервіс import.io має спрощену версію – magic.import.io, де досить ввести лише посилання на сторінку з потрібними даними.
Інструмент безкоштовний (для не більше 10 000 запитів на місяць), для його використання потрібна реєстрація, також можна використовувати за допомогою облікового запису у фейсбуці, Google+ або в деяких інших соціальних мережах.
Розширення браузера Chrome Scraper і Firefox DataScraper
Розширення для браузера Google Chrome (споріднених із ним Chromium, Iron тощо) Scraper перетворює дані з вебсторінки на електронну таблицю.
Встановивши розширення, перейдіть на URL, дані з якого треба взяти. Необхідно виділити текст, що треба перетворити на таблицю, і в контекстному меню, що викликається правою кнопкою миші, вибрати пункт «Scrape similar…». Якщо програма взяла не зовсім те, що треба, є можливість редагувати значення XPath до досягнення потрібного результату. Отримані дані можна експортувати до Google Sheet.
Розширення DataScraper для Firefox працює подібним чином, але замість XPath використовує селектори JQuery.
Розробницькі інструменти браузера
Іноді неможливість скопіювати дані зі сторінки можливо обійти, звернувшись до її вихідного коду. Усі браузери підтримують можливість його перегляду як безпосередньо, так і за допомогою розробницьких інструментів.
Досить часто вебсторінки відображають дані, отримані за допомогою скриптів з інших URL у машиночитаній формі (JSON, XML чи CSV), заповнюючи ними таблиці, мапи й інші конструкції. У такому випадку хорошою альтернативою скрейпінгу цих даних є перехоплення відповідних потоків інформації, їх можна переглянути за допомогою вкладки Network розробницьких інструментів. Сортування за розміром, найменуванням тощо може допомогти знайти серед скриптів той, що отримує потрібні дані. Далі слід скористатися вкладкою Response для копіювання цих даних безпосередньо в текстовий редактор.
Інші засоби скрейпінгу
Різноманіття інструментів скрейпінгу дуже велике і залежить лише від фантазії, технічної підготовки, наявного часу й натхнення. Ось лише декілька посилань на матеріали за темою:
– Як отримати дані з Інтернету (частина посібника «Журналістика даних») texty.org.ua/pg/chapter/newsmaker/read/40161/42409;
– Скрейпінг для журналістів leanpub.com/scrapingforjournalists (англійською мовою).
Імпорт даних із сайтів за допомогою Microsoft Excel
Окрім способів імпорту даних з інтернету за допомогою різних інструментів вебскрейпінгу, описаних у попередньому підрозділі, імпортувати дані з сайту можна за допомогою найпопулярнішої програми електронних таблиць – Microsoft Excel.
Звісно, імпорт даних за допомогою вбудованих можливостей Excel має свої обмеження (наприклад, складність роботи з багатосторінковими документами), але для деяких завдань і для тих, хто звик працювати з програмою Excel, він може бути досить зручним.
Щоб імпортувати дані в таблицю Excel, потрібно вибрати команду From Web (із сайту) у розділі Get External Data (Отримання зовнішніх даних) на вкладці Data (Дані).
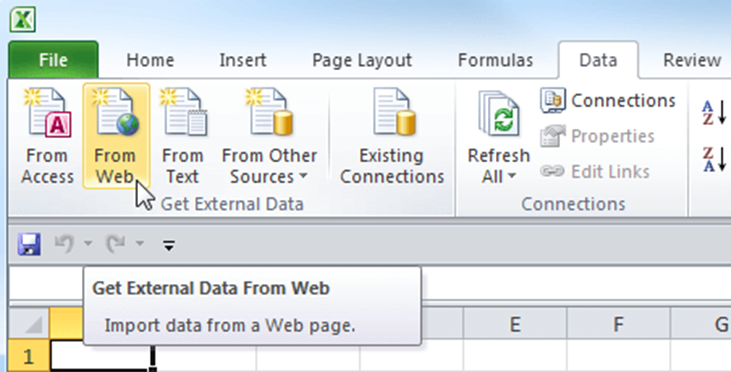
У діалоговому вікні ввести адресу вебсайту, з якого потрібно імпортувати дані, й натиснути Go (Пуск). Сторінка буде завантажена в це ж вікно для попереднього перегляду, її можна погортати і знайти потрібну інформацію.

Перед кожною з web-таблиць є маленька стрілочка, яка вказує, що ця таблиця може бути імпортована в Excel. Необхідно натиснути на неї, щоб виділити дані для завантаження, а потім вибрати Import (Імпорт).
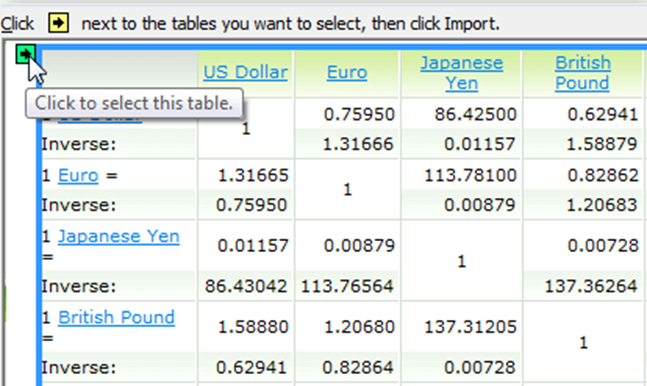
З’явиться повідомлення Downloading (Завантаження) – це означає, що Excel імпортує дані з зазначеної web-сторінки.
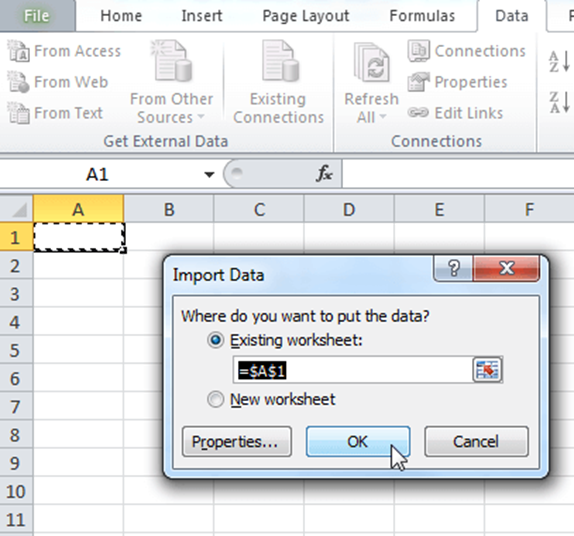
Далі слід вибрати клітинку, в якій будуть розміщені дані з інтернету, і натиснути ОК.
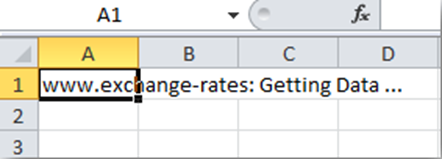
У вибраній комірці з’явиться системне повідомлення про те, що Excel імпортує дані.
Через деякий час інформація з обраної web-сторінки з’явиться в таблиці Excel.
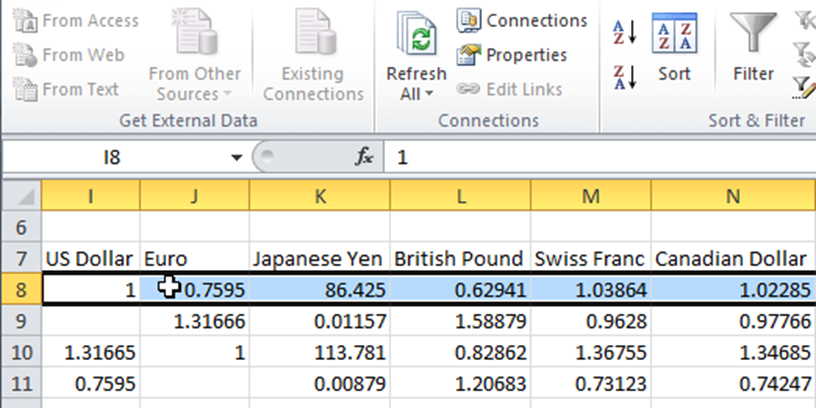
Імпортовані дані можна використовувати так само, як і будь-яку іншу інформацію в Excel. Їх можна застосовувати для побудови графіків, спарклайнів (мініграфіків), формул.

Один із плюсів імпорту даних із сайтів в Excel – це можливість оновлення даних прямо в самій програмі. Так, достатньо натиснути команду Refresh All (Оновити все) на вкладці Data (Дані), і ця дія відправить запит web-сторінці та, якщо є більш свіжа версія даних, запустить процес оновлення в таблиці.
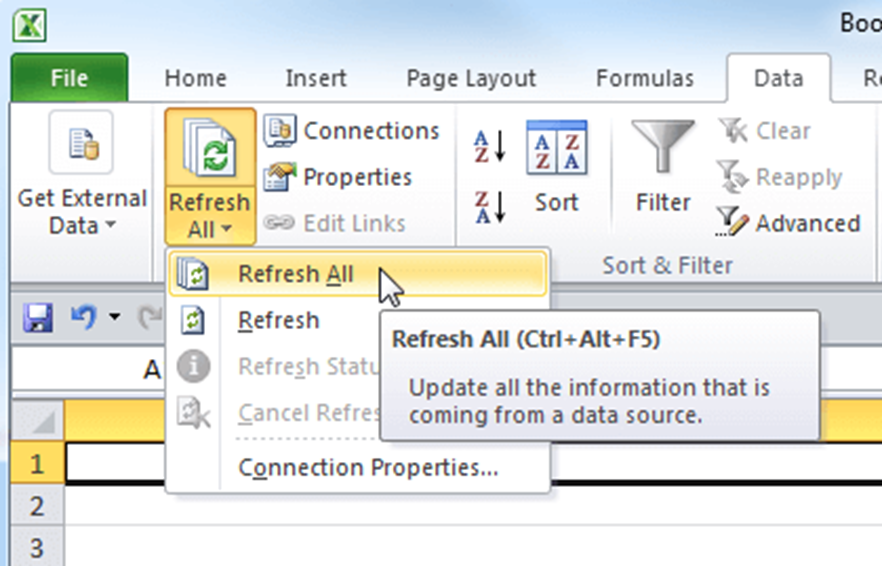
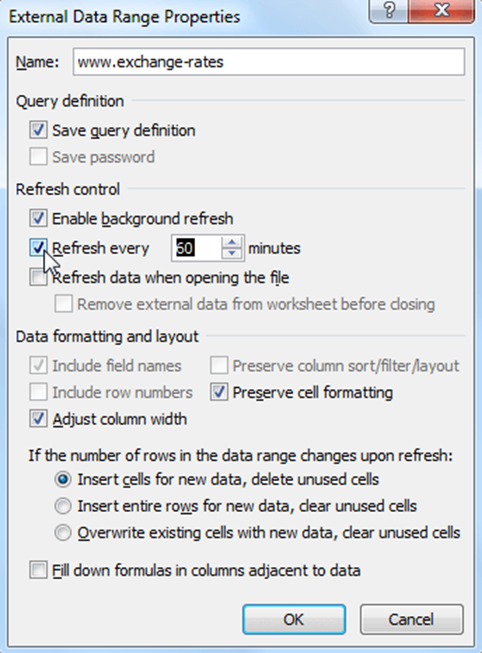
Якщо потрібно, щоб інформація в таблиці автоматично оновлювалась із заданою періодичністю, потрібно вибрати елемент таблиці, що містить динамічні дані, і натиснути команду Properties (Властивості) в розділі Connections (Підключення) на вкладці Data (Дані).
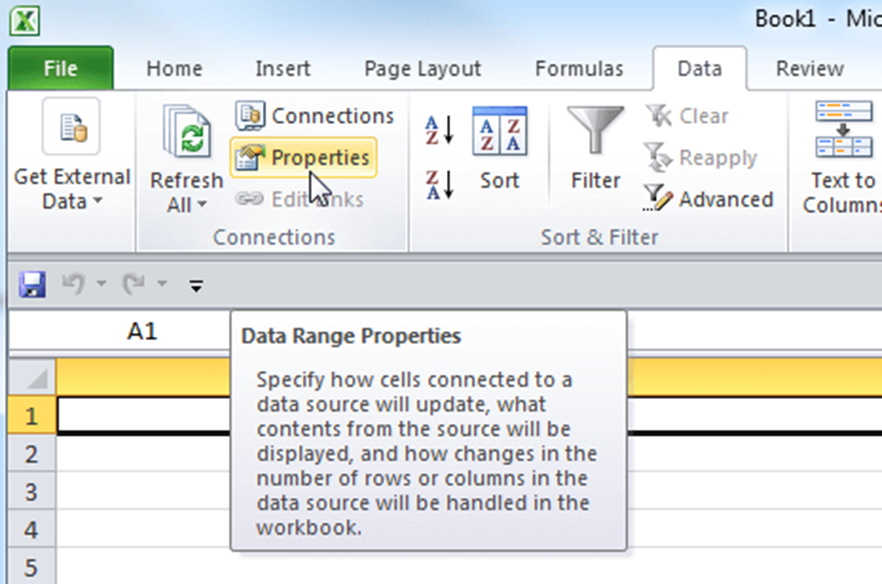
У діалоговому вікні виставити галочку Refresh every (Оновлювати кожні) і вкажіть частоту оновлення в хвилинах. За замовчуванням Excel автоматично оновлює дані кожні 60 хвилин, але можливо встановити будь-який проміжок часу. Або, наприклад, указати Excel оновлювати інформацію кожен раз під час відкриття файлу.